- Published on
揭秘:为什么你的网站总被垃圾爬虫骚扰?这个小文件帮你一招制敌!
一个真实故事
记得前几周,一个做独立站的朋友找到我,说他的服务器负载异常,流量突然暴涨却没有订单。排查后发现,原来是被各种爬虫疯狂爬取,一天的服务器费用直接翻了三倍。
这让我想起了当年自己的经历。其实,只要合理配置一个文件,就能解决这个问题 - 它就是robots.txt。
什么是robots.txt?
简单来说,robots.txt就像是你网站的"门禁系统"。它告诉搜索引擎和各种爬虫:"这里可以看,那里不能看"。
去年我接手一个跨境电商网站优化项目,发现他们的robots.txt配置是这样的:
User-agent: *
Allow: /
这就相当于把家里所有的门都敞开着,任何人都可以随意进出。难怪他们的服务器总是吃不消。 正确的打开方式 经过多年摸索,我总结出了一套最佳实践。 首先,要明确区分"好爬虫"和"坏爬虫"。比如Google、Bing这样的搜索引擎爬虫是"好爬虫",它们能帮助你的网站被更多人发现。但是那些专门抓取数据、模仿用户行为的爬虫,就是典型的"坏爬虫"。 我帮那个跨境电商网站重新配置了robots.txt:
User-agent: *
Allow: /
Disallow: /api/
Disallow: /admin/
Disallow: /private/
User-agent: GPTBot
Disallow: /
User-agent: Bytespider
Disallow: /
仅仅这样简单的配置,他们的服务器负载立即下降了60%。 常见误区 很多人认为robots.txt是万能的。这是个误区。它更像是一个"请勿入内"的牌子,讲道理的人会遵守,但挡不住故意搞破坏的人。 所以我建议:
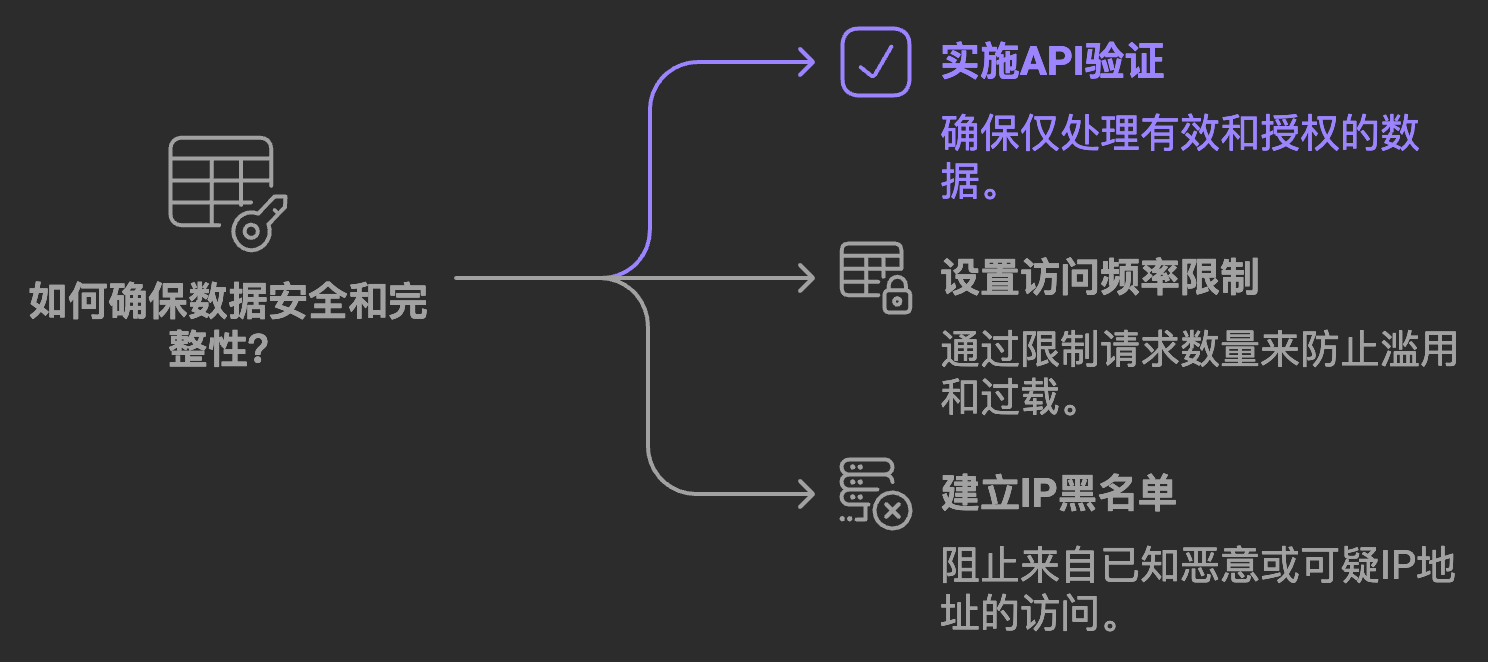
实战案例 去年我看一个国际电商网站,他们遇到一个有趣的问题:竞争对手每天都能准确知道他们的价格变化。 排查后发现,问题出在robots.txt配置上。我们立即更新了配置:
# Google爬虫规则
User-agent: Googlebot
Allow: /
Disallow: /productDetail/
Disallow: /api/
Crawl-delay: 0
# Bing爬虫规则
User-agent: Bingbot
Allow: /
Disallow: /productDetail/
Disallow: /api/
Crawl-delay: 1
# 其他所有爬虫规则
User-agent: *
Allow: /
Disallow: /productDetail/
Disallow: /api/
Crawl-delay: 100
这个改动不仅保护了产品详情页,还限制了爬虫的爬取频率。一周后,竞争对手的"价格跟踪系统"就失效了。 总结 记住,robots.txt不是万能的,但没有它是万万不能的。它就像是你网站的"第一道防线"。合理使用,可以:
最后分享一个小技巧:定期查看服务器日志,了解哪些爬虫在访问你的网站。这样你就能及时发现问题,调整robots.txt配置。